导航

在过去的数十年中,新药研发一直被认为是高风险、高投入的活动。过去业界一直流传着“双十”的说法,即“新药研发需要耗时十年,耗资十亿美元”。而实际上,目前新药研发的成本已远超这个数字,达到了近30亿美元,而且药企还需面对资金背后隐藏的竞争压力。为解决这些问题,基于多组学大数据的人工智能(Artificial Intelligence,AI)正越来越多地被应用于新药研发领域。在本文中,我们将对AI在新药研发中的应用进行探讨。
传统的药物开发流程繁琐复杂,主要包括药物靶点的发现与验证、化合物高通量筛选、先导化合物优化和最终化合物的选择等等,每个步骤都需要投入大量的人力和财力,而精准医学的发展则可以在很大程度上弥补这些缺陷。多组学技术的快速发展及其在临床实践中的常规应用使患者的可识别分子表征直接扩展到基因组、转录组、表观组、蛋白质组等等。这些技术的发展,加上信息技术、计算机科学和计算生物学的进步,为人工智能 (AI) 与药物研发的成功整合创造了沃土。
总体来看,AI对药物研发(包括老药新用)的助力作用体现在很多方面,如生物标志物发现、疾病分型、药物联用方案预测和药物重定位等。接下来,将举例说明AI如何在药物研发中起作用。
生物标志物发现和疾病分型
早在2001年,美国NIH召集的生物标志物定义工作组(Biomarkers Definitions Working Group)就对生物标志物给出了一个定义:它是指“一种可客观检测和评价的特征(characteristic),可作为正常生物学过程、病理过程或治疗干预药理学反应的指示因子”。此后,大量围绕生物标志物的发现、筛选、验证以及应用的工作开始展开。例如,Chen等曾利用TCGA 多组学数据库对14个癌症亚型的40个信号通路相关基因进行了分析,发现DCUN1D1和NSD3可作为癌症相关的潜在生物标志物[1]。随着多组学技术的发展,鉴定出强大的疾病特异性生物标志物已逐渐成为推进癌症精准医学的基础,而AI则为识别更加复杂的生物标志物特征提供了机会。下面的实例带我们直观感受AI如何在生物标志物发现方面起重要作用:
2021年7月,Wolfgang Huber团队在Nature Cancer上发表了一篇研究性论文,主要利用基于多组学技术的AI算法对慢性淋巴细胞白血病 (CLL) 的Biomarker进行了探索[2]。
主要研究结果
1.设计算法,利用基因组(体细胞突变和拷贝数变异)、表观基因组(DNA 甲基化)、转录组(RNA表达)和离体药物反应等多组学数据鉴定出与患者OS和TTT相关的潜在因子 CLL-PD(即CLL proliferative drive,它是一种与CLL恶性程度相关的综合评价因素,后续研究表明其与mTOR-MYC-OXPHOS通路的活性紧密相关)
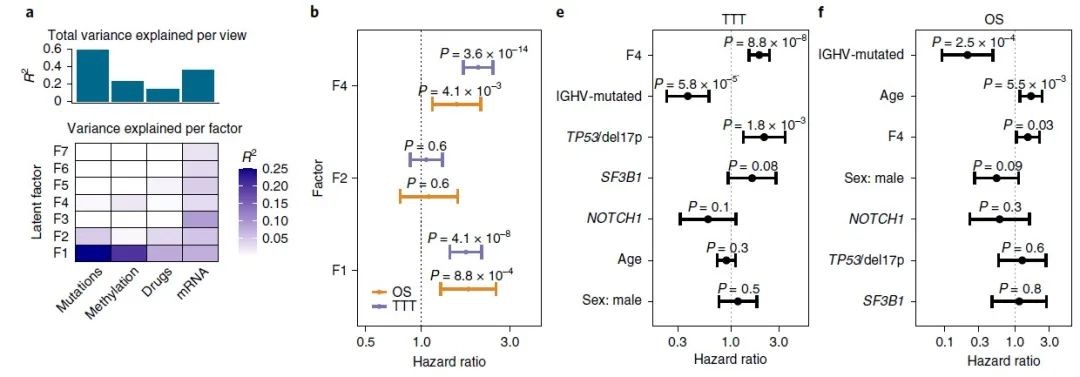
图1 多组学数据可鉴定出与临床结果相关的潜在因子CLL-PD[1]
2. 利用CLL-PD作为Biomarker可改善患者分层:通过将CLL-PD应用于其他独立队列,结果表明CLL-PD是患者人群TTT和OS的重要预测分子(图2)。因此,作者得出结论,高CLL-PD是与更具侵袭性的慢性淋巴细胞白血病和更早的治疗需求相关的肿瘤特性。
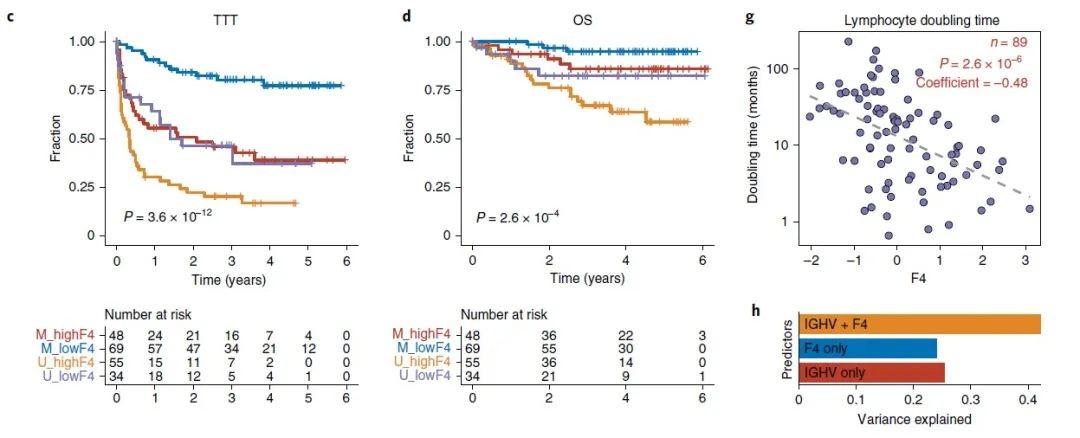
图2 CLL-PD是TTT和OS的重要预测分子[1]
3. 为了进一步了解 CLL-PD的生物学特性,作者首先从基因组开始研究了它的分子特征。结果发现,高 CLL-PD会导致TP53、NOTCH1、SF3B1等癌症相关基因的突变频率增加。接下来,作者还对CLL的DNA甲基化进行了研究。发现较高的 CLL-PD 具有低甲基化特征(图3)。根据以往报道,DNA 甲基化的整体缺失被认为是 CLL 的标志性特征,并且与较差的预后有关。由此,作者进一步确认了CLL-PD作为Biomarker的分子机制和临床相关性。

图 3 CLL-PD与基因突变和基因组DNA甲基化的相关性[1]
由此可见,对比传统的、需进行大量探索性实验的生物标志物探索途径,多组学数据挖掘和AI算法在生物标志物的开发中具有巨大优势。它能够快速准确地挖掘出患者分型信息,提供具有理论基础和竞争力的药物靶点。这一点可以帮助药企在药物开发过程中占得先机,迅速明确开发方向,同时也避免不必要的过度投入。
药物联用方案预测和药物重定位
在癌症治疗过程中,特别是当产生获得性耐药性时,单一疗法往往会存在效力低下的问题。此时,药物联用就可能利用药物协同作用以克服耐药性。目前,大多数药物组合要么遵循“双重打击”的策略,要么针对独立的通路或疾病机制。但在同时存在多种药物适用于同一适应症的情况下,可能的药物组合也就会随之呈现指数增长。
与此同时,很多药企也面临着为已有药物开发新的适应症的问题。传统上,无论是探索新的药物组合还是老药新用都主要靠依靠系统生物学方法,并且仅使用药物自身数据作为验证实验。例如,利用单药特征来推导药物功能网络,通过搜索在互补疾病特异性信号网络中富集的药物来提取有效的药物组合。但这种探索方式往往伴随着主观性和盲目性,并不利于设计出最优的药物组合和开发新适应症方案。相比之下,基于多组学数据的AI算法则可以在更广泛的背景下,优先制定出最有希望成功的策略,同时控制药物毒性的增加。
2013年,Stephen TC Wong团队在Cancer Res期刊发表了一篇研究性论文就很好展示了如何利用已有药物开发新适应症,其探讨了舒尼替尼(已经被批准用于晚期肾细胞癌治疗)和达沙替尼(已经被批准用于慢性髓性白血病治疗)在乳腺癌的脑转移治疗中的潜在应用[3]。
作者团队在前期研究中,开发了一种基于实验数据和组学分析的新型药物重定位分析策略,称为癌症信号桥 (CSB),以系统地研究潜在的信号机制。CSB由8个模块构成,分别为6个计算模块和2个乳腺癌脑转移实验模块(图4)。其中计算模块包括差异分析、富集分析、癌症信号桥(CSB)分析、网络机制分析、生存分析和再定位分析,两个实验模块包括靶标验证和药效测定。CSB 能够将已知的经典信号通路扩展到其编码的基因和与癌症相关的遗传疾病,包括与癌症发生发展密切相关的蛋白质。
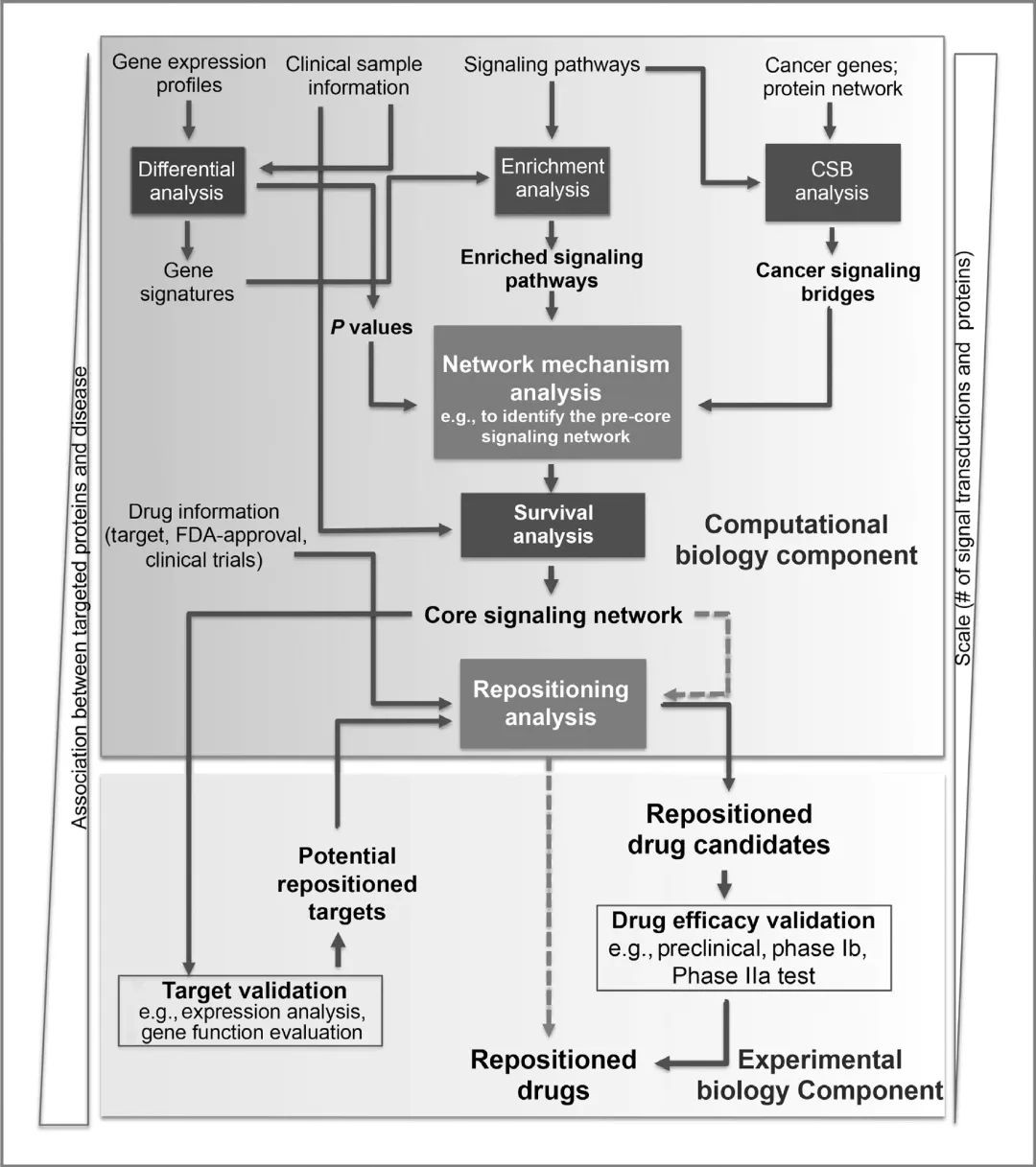
图4 CSB系统的工作原理[3]
利用CSB分析,作者首先对特定的信号通路进行了计算建模。利用患者的基因表达特征和已知信号通路,对乳腺癌的大脑、肺和骨转移激活的上游信号通路进行了识别分层。随后,作者通过多目标优化模型推导出了每个转移类型的特定下游信号通路,并确定了乳腺癌的脑、肺和骨转移的下游蛋白质信号网络。
应用生存分析模块,作者将假定的信号通路与患者的可用临床信息(例如无转移生存时间)进行了关联,过滤出对患者存活和转移发生至关重要的高置信度蛋白信号途径,以及以这些蛋白质和基因为靶点的药物。
随后,作者利用计算模块确定了15个可能用作再定位的候选药物,并发现其中有10种药物具有穿透血脑屏障的能力。其中,之前尚无报道舒尼替尼和达沙替尼可能与乳腺癌的脑转移相联系,而实验模块的验证结果表明这两种药物均显示出了显著降低乳腺癌脑转移的潜力。基于这些研究成果,作者开展了相关临床试验。
通过上述案例可以看出,基于多组学大数据的AI正在越来越多地被应用于药物研发领域。目前,国际上最有影响力的肿瘤多组学研究项目莫过于TCGA (The Cancer Genome Atlas),它也是世界上最大的癌症基因信息数据库。普瑞基准联合创始人梁晗博士即为TCGA核心科学家之一,是多种癌症临床和预测科学组主席。普瑞基准基于大量文献、临床试验和患者数据,应用AI自主打造了多组学数据挖掘系统AIBERT,致力于建立临床、科研和药企开发策略之间的桥梁,助力药企的新药研发决策和转化研究。
AIBERT是由AI驱动的肿瘤组学大数据挖掘系统(图5),其主要具备四项功能:(1)更高效地寻找新的药物靶点;(2)开发更有效的生物标志物;(3)探索更合理的药物联用方案;(4)扩展药物新的适应症。通过研发关键环节策略的优化,加快新药获批速度,提升获批成功率。
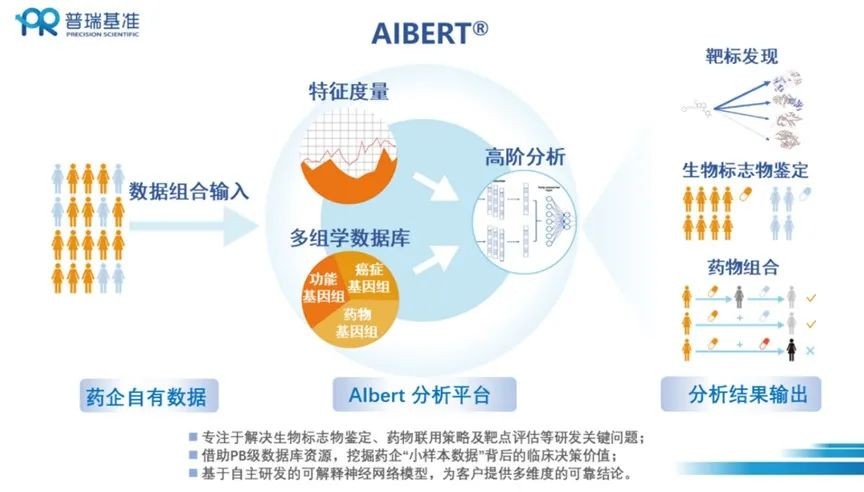
图5 AIBERT系统工作原理
AIBERT的诞生,可以满足药企创新药研发、转化研究和临床精准治疗的实际需求,新时代背景下契合了肿瘤药物研发的思路。这一切,也正如普瑞基准创始人兼CEO季序我博士强调的:“不论是药企还是临床医生,都希望找出最优的治疗方法,而AIBERT正是为解决医疗本质问题而打造的一把利器。”